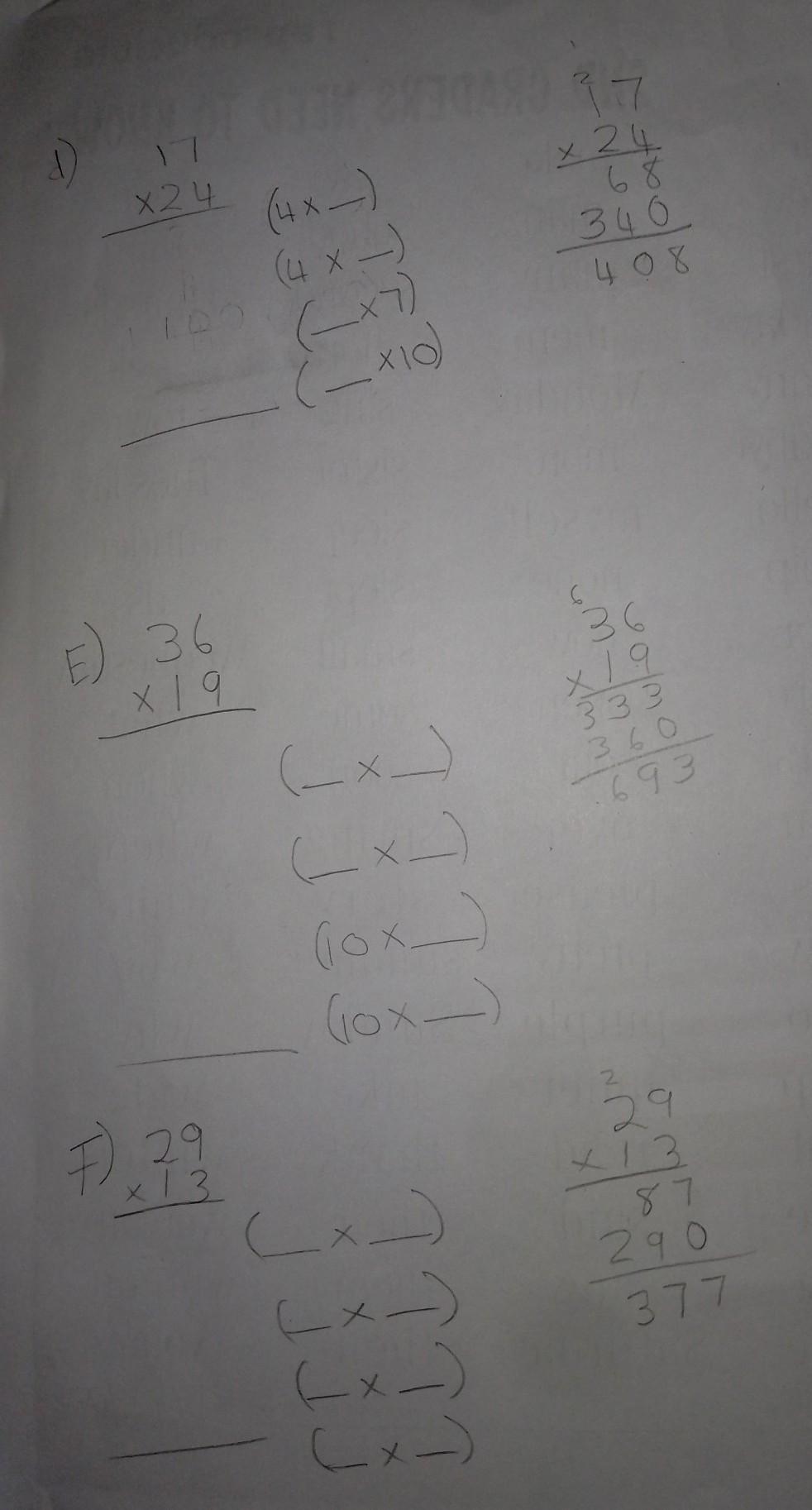
Answers
Answer:
D) 408
E) 684
F) 377
Step-by-step explanation:
In these problems, we can simplify the multiplication using these steps:
1. split each number into a tens and ones place
2. multiply each place of the bottom number by both places of the top number (but remember that a digit in the tens place has a zero after it)
3. add the resulting values
D) First, we can split each number into a tens and ones place:
17 = 10 and 7
24 = 20 and 4
Next, we can multiply each digit of the bottom number by both digits of the top number:
(4 × 7)
(4 × 10)
(20 × 7)
(20 × 10)
Finally, we can add all of these values:
(4 × 7) + (4 × 10) + (20 × 7) + (20 × 10)
= 28 + 40 + 140 + 200
= 408
E)
36 = 30 and 6
19 = 10 and 9
Multiplying the places:
(9 × 6)
(9 × 30)
(10 × 6)
(10 × 30)
Adding these values:
(9 × 6) + (9 × 30) + (10 × 6) + (10 × 30)
= 54 + 270 + 60 + 300
= 684
F)
29 = 20 and 9
13 = 10 and 3
Multiplying the places:
(3 × 9)
(3 × 20)
(10 × 9)
(10 × 20)
Adding these values:
(3 × 9) + (3 × 20) + (10 × 9) + (10 × 20)
= 27 + 60 + 90 + 200
= 377
Related Questions
A weather forecaster predicts that the May rainfall in a local area will be between three and six inches but has no idea where within the interval the amount will be. Let x be the amount of May rainfall in the local area, and assume that x is uniformly distributed over the interval three to six inches. (a) Write the formula for the probability curve of x. f(x) = / for < x < (b) What is the probability that May rainfall will be at least four inches? At least five inches?
Answers
The probability that May rainfall will be at least five inches can be calculated as: P(x ≥ 5) = (6-5) / (6-3) = 1/3
(a) The formula for the probability curve of x is:
f(x) = 1 / (6-3) = 1/3 for 3 ≤ x ≤ 6
This is because x is uniformly distributed over the interval three to six inches, which means that all values within the interval are equally likely to occur. The probability of any specific value of x occurring is therefore equal to the width of the interval (6-3 = 3) divided by the total length of the interval, which is 1/3.
(b) The probability that May rainfall will be at least four inches can be calculated as follows:
P(x ≥ 4) = (6-4) / (6-3) = 2/3
This is because the probability of x being greater than or equal to 4 is equal to the width of the interval from 4 to 6 (which is 6-4 = 2) divided by the total length of the interval (which is 6-3 = 3).
This is because the probability of x being greater than or equal to 5 is equal to the width of the interval from 5 to 6 (which is 6-5 = 1) divided by the total length of the interval (which is 6-3 = 3).
Know more about probability here;
https://brainly.com/question/30034780
#SPJ11
Laseright Software discovered a number of defects in their software and counted them daily. They plotted the number of defects after they computed an average, Upper and Lower control limits. They plotted a _________type control chart for _________ .
Answers
Laseright Software discovered several defects in their software and counted them daily. They plotted the number of defects after they computed average, Upper, and Lower control limits. They plotted a C-type control chart for Attributes
Laseright Software has implemented a C-type control chart for Attributes to monitor the number of defects that they discovered in their software. A control chart is a statistical tool that is used to monitor a process and to ensure that it is operating within certain limits. It helps to identify any patterns or trends in the process and enables the organization to take corrective actions when necessary.
The C-type control chart for Attributes is used to monitor the count of defects in a process. It is plotted with an average, upper control limit, and lower control limit. The average is the mean number of defects that were discovered over a specific period. The upper and lower control limits are determined based on the variability of the data and are used to identify when the process is out of control.
In summary, Laseright Software's implementation of a C-type control chart for Attributes is a proactive approach to monitoring their software development process. It allows them to identify any defects in their software and take corrective actions to improve their product and ensure customer satisfaction.
Know more about control chart here:
https://brainly.com/question/29317670
#SPJ11
The heat evolved in calories per gram of a cement mixture is approximately normally distributed. The mean is thought to be 100, and the standard deviation is 5. Calculate the probability of a type II error if the true mean heat evolved is 103 and
Answers
To calculate the probability of a type II error, we need to first determine the critical value for the test. This can be found using the formula:
Critical value = mean + (z-score for desired level of significance) x (standard deviation/square root of sample size)
Assuming a 5% level of significance and a sample size of 25, the z-score for a one-tailed test is 1.645. Plugging in the values, we get:
Critical value = 100 + (1.645) x (5/sqrt(25)) = 101.645
Next, we need to determine the probability of failing to reject the null hypothesis (i.e. making a type II error) when the true mean heat evolved is actually 103. This can be found using a normal distribution table or calculator:
z-score = (critical value - true mean)/standard deviation = (101.645 - 103)/5 = -0.31
Using the normal distribution table, the probability of a z-score of -0.31 or less is 0.3783. Therefore, the probability of making a type II error is approximately 38%.
In summary, if the true mean heat evolved is 103 and we are using a one-tailed test with a 5% level of significance and a sample size of 25, there is a 38% chance that we will fail to reject the null hypothesis and make a type II error.
learn more about probability here:brainly.com/question/30034780
#SPJ11
Solve for x, rounding to the nearest hundredth
68x3^x/2=136
Answers
The solution of the given expression 68 × [tex]3^{(x/2)}[/tex] = 136 for x is equal to 1.26 ( rounded to the nearest hundredth ).
The expression is equal to ,
68 × [tex]3^{(x/2)}[/tex] = 136
Divide both the side of the expression by 68 we get,
⇒ [ 68 × [tex]3^{(x/2)}[/tex] ] / 68 = ( 136 ) / 68
⇒ [tex]3^{(x/2)}[/tex] = 2
Take logarithmic function on both the side of the expression we get,
⇒ ( x / 2) log 3 = log 2
⇒ ( x / 2) = log 2 / log 3
⇒ x = 2 × ( log 2 / log 3 )
⇒ x = 2 × ( 0.3010 / 0.4771 )
⇒ x = 2 × 0.6309
⇒ x = 1.2618
Therefore, the solution of the expression for x rounded to the nearest hundredth is x ≈ 1.26.
Learn more about the solution here
brainly.com/question/12730996
#SPJ1
The given question is incomplete, I answer the question in general according to my knowledge:
Solve the expression for x, rounding to the nearest hundredth
68 × 3^( x/2 ) = 136
An administrator of a TANF program is concerned about the length of time hard-to-place clients were able to gain employment. He wants to contrast the average length of time at a job for his clients with the national average. What statistic should he use
Answers
The administrator should use the mean duration of employment for his clients to compare it with the national average. This will help determine if his hard-to-place clients have shorter or longer job durations than the average.
What statistic should be used to compare the job duration of TANF program clients with the national average?To contrast the average length of time at a job for his clients with the national average, the administrator of the TANF program should use the mean duration of employment for his clients and compare it to the national average.
This would provide a measure of the central tendency of employment durations for his clients and allow him to compare this measure to the corresponding national statistic.
However, it is important to note that this measure alone may not provide a complete picture of employment outcomes for hard-to-place clients in the TANF program.
The administrator may also want to consider other statistical measures such as the median duration of employment or the standard deviation to get a better understanding of the distribution of employment durations among his clients.
The median duration of employment would provide a measure of the middle value of employment durations, which may be a more representative statistic if there are outliers or extreme values in the data.
The standard deviation would provide a measure of the variability in employment durations among his clients, which would be useful in determining whether there is a wide range of outcomes or if most clients have similar employment durations.
In addition to statistical measures, the administrator may also want to consider qualitative factors such as the types of jobs his clients are able to secure and whether they are able to advance in their careers over time.
This would provide a more nuanced understanding of employment outcomes and allow for a more comprehensive evaluation of the effectiveness of the TANF program in supporting hard-to-place clients in gaining and maintaining employment.
Learn more about administrator statistic
brainly.com/question/28218199
#SPJ11
A store sells variety packs of granola bars. The table shows the types of bars in each pack . Mason says that for every 7 bars in a pack, there is 1 cinnamon bar. Do you agree? Explain.
Answers
It is not true that for every 7 bars in a pack, there is 1 cinnamon bar.
Let's assume that there are 7 packs, each containing 1 cinnamon bar, 4 honey bars, and 3 peanut butter bars.
Then, the total number of bars in the 7 packs would be:
1 (cinnamon) x 7 packs = 7 cinnamon bars
4 (honey) x 7 packs = 28 honey bars
3 (peanut butter) x 7 packs = 21 peanut butter bars
The total number of bars in the packs would be:
7 cinnamon bars + 28 honey bars + 21 peanut butter bars = 56 bars
So, the ratio of cinnamon bars to the total number of bars would be:
1 cinnamon bar : 56 total bars
This can be simplified to 1/56
To learn more on Fractions click:
https://brainly.com/question/10354322
#SPJ1
An operating characteristic (OC) curve describes: how many defects per unit are permitted before rejection occurs. the sample size necessary to distinguish between good and bad lots. the most appropriate sampling plan for a given incoming product quality level. how well an acceptance sampling plan discriminates between good and bad lots. None of these.
Answers
An operating characteristic (OC) curve describes how well an acceptance sampling plan discriminates between good and bad lots.
It is a graphical representation of the probability of acceptance for different levels of quality, and it shows the trade-off between the producer's and consumer's risks.
The OC curve plots the probability of accepting a lot with a certain percentage of defects, and it is based on the sample size and the acceptance and rejection numbers defined by the sampling plan. The OC curve can be used to evaluate the performance of different sampling plans, compare their effectiveness, and determine the sample size necessary to achieve a certain level of quality. In general, a good acceptance sampling plan should have a high probability of rejecting bad lots and a low probability of rejecting good lots, which means it should have a steep OC curve that approaches the upper-left corner of the graph. However, the shape of the OC curve depends on several factors, such as the lot size, the inspection level, and the quality level, so it is important to choose the most appropriate sampling plan for a given situation to ensure that the desired quality is achieved.Know more about the operating characteristic (OC) curve
https://brainly.com/question/13671411
#SPJ11
In a simple linear regression model, if all of the data points fall on the sample regression line, then the standard error of the estimate is
Answers
In a simple linear regression model, the standard error of the estimate (also known as the standard deviation of the residuals) measures the variability or scatter of the observed data points around the sample regression line.
It is an important measure of the accuracy of the regression model and helps us to estimate the uncertainty in making predictions.
If all of the data points fall exactly on the sample regression line, then the residuals (i.e., the differences between the observed values and the predicted values) will be zero for each data point. This means that there is no variability or scatter in the data points around the regression line, and hence the standard error of the estimate will also be zero.
However, this scenario is highly unlikely in real-world situations, as there will always be some random error or measurement noise that affects the observed data points. Therefore, it is important to interpret the standard error of the estimate in the context of the data and the regression model. A smaller standard error of the estimate indicates a better fit of the regression line to the data, whereas a larger standard error of the estimate indicates more variability or scatter in the data points around the regression line.
To know more about linear regression model, refer to the link below:
https://brainly.com/question/15127004#
#SPJ11
in 1940 john atansoff a physicist from iows state university wanted to solvve a 29 x 29 linear system of equations. how many arithmetic operations would this have required.
Answers
In 1940, John Atanasoff, a physicist from Iowa State University, wanted to solve a 29 x 29 linear system of equations. To solve this system using Gaussian elimination, it would have required approximately 29^3/3 = 24389 arithmetic operations.
In 1940, John Atanasoff developed the Atanasoff-Berry Computer (ABC), which was the first electronic computer. Atanasoff wanted to use the ABC to solve a 29 x 29 linear system of equations.
29^3 = 24389Therefore, solving a 29 x 29 linear system of equations using Gaussian elimination would have required approximately 24,389 arithmetic operations. However, it's important to note that this estimate is based on the assumption that the ABC could perform arithmetic operations at a speed comparable to modern computers. In reality, the ABC was much slower, and so the actual number of operations required would have been much higher.
Know more about the linear system of equations
https://brainly.com/question/14323743
#SPJ11
(-7x^5/14x)^-3 Simplify
Answers
The simplified form of the given expression, (-7x^5/14x)^-3, is -8x⁻¹²
Simplifying an expressionFrom the question we are to simplify the given expression
From the given information,
The given expression is
(-7x^5/14x)^-3
This expression can be properly written as:
(-7x⁵/14x)⁻³
The expression can be simplified as shown below:
(-7x⁵/14x)⁻³
(-7x⁵)⁻³ / (14x)⁻³
[1 / (-7x⁵)³] / [1 / (14x)³]
[1 / (-7)³ × (x⁵)³] / [1 / (14)³ × (x)³]
[1 / -343 × (x¹⁵)] / [1 / 2744 × x³]
[1 / -343x¹⁵] / [1 / 2744x³]
= [1 / -343x¹⁵] × [2744x³ / 1]
= 2744x³ / -343x¹⁵
= -2744/343 × x³ / x¹⁵
= -8 × x³ / x¹⁵
= -8x³ / x¹⁵
= -8 × x³ ⁻ ¹⁵
= -8 × x⁻¹²
= -8x⁻¹²
Hence, the simplified expression is -8x⁻¹²
Learn more on Simplifying an expression here: https://brainly.com/question/15775046
#SPJ1
Increasing the significance level of a hypothesis test (say, from 1% to 5%) will cause the p-value of an observed test statistic to:___________
Answers
Increasing the significance level of a hypothesis test, for example from 1% to 5%, does not directly affect the p-value of an observed test statistic. The p-value is determined by the data and the test statistic, not the significance level.
However, changing the significance level will affect your decision about whether to reject or fail to reject the null hypothesis.
The significance level, denoted by alpha (α), represents the probability of making a Type I error, which occurs when you incorrectly reject the null hypothesis when it is true. By increasing the significance level, you are allowing for a higher probability of making a Type I error, making the test less stringent.
The p-value is the probability of obtaining a test statistic at least as extreme as the observed value, assuming that the null hypothesis is true. If the p-value is less than or equal to the significance level, you reject the null hypothesis in favor of the alternative hypothesis.
In conclusion, increasing the significance level of a hypothesis test will not cause the p-value of an observed test statistic to change. Instead, it will change the threshold at which you decide to reject the null hypothesis, making the test more likely to reject the null hypothesis, and increasing the chance of making a Type I error.
Learn more about hypothesis test here:
https://brainly.com/question/30588452
#SPJ11
Coach Burke was emphasizing proper hitting mechanics during Tuesday's practice at the ball field. He was extremely impressed to see several of his players hit the ball off the outfield fence and a few over the fence during batting practice. The players increased their hitting distance by:
Answers
Coach Burke's emphasis on proper hitting mechanics during Tuesday's practice at the ball field led to impressive results among the players. By focusing on elements such as stance, grip, and swing, the players were able to improve their overall hitting performance.
Their increased hitting distance can be attributed to several factors.
First, a balanced and comfortable stance allowed the players to transfer their weight effectively and generate more power in their swings. Secondly, a firm yet relaxed grip on the bat helped maintain proper bat control, ensuring that the players were able to hit the ball with maximum force. Additionally, an efficient and smooth swing, with a proper follow-through, allowed the players to make solid contact with the ball, thus increasing the hitting distance.
As a result of Coach Burke's guidance in refining these aspects of hitting mechanics, the players were able to hit the ball off the outfield fence and even over the fence during batting practice.
This improvement in hitting distance is a testament to the importance of mastering the fundamentals of baseball and the impact of quality coaching on player performance.
To learn more about factors click here
brainly.com/question/29128446
#SPJ11
Compute the following weighted average. You may need to add information to the given table to help you make the correct computations.
Over a given time period, a convenience store had visits from delivery trucks in the following categories with the indicated charge per delivery. What is the average delivery charge the store pays each week?
Category: Deliveries per week: Per Delivery Charge:
Snacks - 3 $25.00
Alcohol - 2 $100.00
Dairy - 4 $75.00
Answers
The weighted average delivery charge the store pays each week is approximately $63.89.
To find the average delivery charge the store pays each week, we need to calculate the weighted average of the delivery charges, where the weights are the number of deliveries in each category.
To do this, we need to first calculate the total cost of deliveries for each category
Snacks: 3 × $25.00 = $75.00
Alcohol: 2 × $100.00 = $200.00
Dairy: 4 × $75.00 = $300.00
Next, we need to calculate the total number of deliveries per week
Total deliveries per week: 3 + 2 + 4 = 9
Finally, we can calculate the weighted average delivery charge as
Weighted average = (Total cost of deliveries) / (Total number of deliveries)
Weighted average = ($75.00 + $200.00 + $300.00) / 9
Weighted average = $575.00 / 9
Weighted average ≈ $63.89
To know more about weighted average here
https://brainly.com/question/27796696
#SPJ1
In a survey of 100 students, 60% wake up with an alarm clock.
Of those who wake up with an alarm clock, 80% exercise to
begin the day. Among those who do not use an alarm clock,
25% exercise to begin the day. Construct a two-way frequency
table to display the data.
Answers
A two-way frequency table for the data:
How to solveHere's a two-way frequency table for the data:
| Alarm Clock | No Alarm Clock | Total
Exercise | 48 | 10 | 58
No Exercise | 12 | 30 | 42
Total | 60 | 40 | 100
A two-way frequency table, otherwise referred to as a contingency table, is a chart that showcases the frequencies or reckonings of two categorical variables.
The display has two columns and two or greater rows, with each row manifesting a single grouping of the primary element and each column demonstrating one type of the second constituent.
The cells of this array demonstrate the frequency or amount of appearances that abide by both categories. A two-way frequency table is perennially utilized in data analysis and statistics to investigate the association between two distinct categorical factors.
Read more about surveys here:
https://brainly.com/question/14610641
#SPJ1
4.12. Based on the U.S. data for 1965-IQ to 1983-IVQ (n = 76), James Doti and Esmael Adibi25 obtained the following regression to explain personal con- sumption expenditure (PCE) in the United States. Ý, = – 10.96 +0.93X2 – 2.09031 t =(-3.33) (249.06) (-3.09) R2=0.9996 F=83,753.7 where Y=the PCE ($, in billions) X2 = the disposable (i.e., after-tax) income ($, in billions) X3 = the prime rate (%) charged by banks a. What is the marginal propensity to consume (MPC)—the amount of additional consumption expenditure from an additional dollar's personal disposable income? b. Is the MPC statistically different from 12 Show the appropriate testing procedure c. What is the rationale for the inclusion of the prime rate variable in the model? A priori, would you expect a negative sign for this variable? d. Is bz significantly different from zero? e. Test the hypothesis that R2 =0. f. Compute the standard error of each coefficient.
Answers
a. The marginal propensity to consume (MPC) is the coefficient of X2, which is 0.93. This means that for every additional dollar of disposable income, individuals will consume 93 cents more.
b. To test if the MPC is statistically different from 1, we need to perform a t-test on the coefficient of X2. The t-value is 249.06, which is much larger than the critical value of 1.96 at a 5% level of significance. Therefore, we can reject the null hypothesis that the MPC is equal to 1 and conclude that it is statistically different.
c. The prime rate variable is included in the model because it affects the cost of borrowing, which can impact consumption expenditure. A priori, we would expect a negative sign for this variable because as the prime rate increases, borrowing becomes more expensive, which would discourage spending.
d. The coefficient for X3 is not given in the equation, so we cannot determine if it is significantly different from zero.
e. To test the hypothesis that R2 = 0, we can perform an F-test. The calculated F-value is 83,753.7, which is much larger than the critical value of 1.64 at a 5% level of significance. Therefore, we can reject the null hypothesis and conclude that the model has a significant amount of explanatory power.
f. The standard error of each coefficient can be found in the parentheses next to the t-values. The standard errors for the intercept, X2, and X3 are 3.33, 249.06, and 3.09, respectively.
learn more about marginal propensity here: brainly.com/question/17930875
#SPJ11
Which model assumes a constant percent rate of growth?
Linear.
Quadratic.
Cubic.
Exponential.
Answers
The exponential model is the best model to use when the quantity being measured grows or decays at a steady percent rate over time. It is important to choose the appropriate model based on the nature of the relationship between the variables being studied.
The model that assumes a constant percent rate of growth is the exponential model. This model describes a situation where the quantity being measured grows or decays at a steady percent rate over time. The growth or decay can be expressed as an exponential function with a base greater than 1 for growth, or between 0 and 1 for decay.
In contrast, the linear model assumes a constant rate of change and is best used when there is a linear relationship between two variables. The quadratic model assumes a parabolic relationship between two variables and is best used when the relationship between the variables is curved. The cubic model assumes a relationship between two variables that is more curved than the quadratic model.
Learn more about exponential model here :-
https://brainly.com/question/29564778
#SPJ11
The mechanic averages 15 miles per hour for the round trip. How long is the mechanic away from the shop
Answers
The time the mechanic is away from the shop is 2 hours.
To find the time the mechanic is away from the shop, we need to know either the distance of the round trip or the speed of the mechanic on one of the legs of the trip.
For example, if we know that the distance of the round trip is 30 miles, we can use the formula:
time = distance / speed
where speed is the average speed for the round trip, which is given as 15 miles per hour.
So, the time the mechanic is away from the shop would be:
time = 30 miles / 15 miles per hour = 2 hours
But without knowing the distance of the round trip or the speed of the mechanic on one of the legs of the trip, we cannot calculate the time the mechanic is away from the shop.
for such more question on distance
https://brainly.com/question/12356021
#SPJ11
if a jaguar has traveled 25.5 miles in an hour if it continues at the same speed how far will it travel in 10 hours ps: this is due in about 60 seconds please hurry with explnation
Answers
Answer:255
Step-by-step explanation:
25.5 * 10 = 255 so the answer would be 255
Answer: 255 miles
Step-by-step explanation: 25.5 miles times 10 hours will get you 255 miles away.
A new train goes 20% further in 20% less time than an old train. By what percent is the average speed of the new train greater than that of the old train
Answers
The average speed of the new train is greater than that of the old train by 50%.
Let's assume that the old train traveled a distance of "d" in "t" time, with an average speed of "s" (where s = d/t).
The new train travels 20% further than the old train, which means it travels a distance of 1.2d. It also travels this distance in 20% less time than the old train, which means it takes 0.8t time to cover the distance.
So, the average speed of the new train is (1.2d)/(0.8t) = 1.5d/t.
The percent increase in average speed of the new train compared to the old train is:
[(1.5d/t - s)/s] x 100%
Substituting s = d/t, we get:
[(1.5d/t - d/t)/(d/t)] x 100%
Simplifying the expression, we get:
(0.5d/t) x 100%
Therefore, the average speed of the new train is greater than that of the old train by 50%.
Know more about average speed here:
https://brainly.com/question/4931057
#SPJ11
If a many-to-many-to-many relationship is created when it is not appropriate to do so, how can the problem be corrected?
Answers
If a many-to-many-to-many relationship is created when it is not appropriate to do so, the problem can be corrected by re-designing the database schema to remove the unnecessary relationship.
Here are some steps you can follow to correct the problem:
Analyze the existing database schema to identify the many-to-many-to-many relationship and the tables involved in it.
Evaluate the relationship to determine whether it is necessary or not. If it is not, remove it from the schema.
If the relationship is necessary, analyze the tables and their attributes to identify the primary keys and foreign keys involved in the relationship.
Create a new table to serve as an intermediary between the tables involved in the relationship.
Update the foreign keys in the related tables to point to the primary keys in the new intermediary table.
Migrate the data from the existing tables to the new intermediary table.
Test the new database schema to ensure that it functions correctly and that all data is correctly retrieved and stored.
Overall, the process of correcting a many-to-many-to-many relationship involves re-evaluating the database schema and modifying it as necessary to ensure that it is properly designed to store and retrieve data efficiently and accurately.
for such more question on database schema
https://brainly.com/question/12125305
#SPJ11
In how many different ways can five women and three men stand in a line if no two men stand next to each other
Answers
There are 24,000 different ways to arrange five women and three men in a line if no two men stand next to each other.
If no two men can stand next to each other, we can first arrange the women in the line, and then insert the men in the spaces between the women.
There are 5! ways to arrange the 5 women in the line.
We can visualize the 5 women standing like this:
W W W W W
To ensure that no two men stand next to each other, we need to insert the 3 men into the 4 spaces between the women. We can use the stars and bars method to count the number of ways to do this.
We can represent the spaces between the women with 4 bars:
| | | | |
To insert the 3 men into these spaces, we need to place 3 stars in these 4 spaces. We can use the stars and bars formula to calculate the number of ways to do this:
C(3 + 4 - 1, 3) = C(6, 3) = 20
So there are 20 ways to arrange the 3 men in the spaces between the 5 women.
Therefore, the total number of ways to arrange 5 women and 3 men such that no two men stand next to each other is:
5! × 20 = 24,000
for such more question on word problem
https://brainly.com/question/13818690
#SPJ11
If possible please show the work
Answers
The value of sin(x) that supports Todd's claim is (A), ((m+n)√2)/(2√m²+n²) = (m+n) / √[(m+n)² + (m-n)²]
How to prove claims?To solve this problem, use the identity:
tan(x) = sin(x)/cos(x)
Since Todd claims that:
tan(x) = (m+n)/(m-n)
Rewrite this as:
sin(x)/cos(x) = (m+n)/(m-n)
Multiplying both sides by cos(x):
sin(x) = cos(x) * (m+n)/(m-n)
To find the value of sin(x) that supports Todd's claim, simplify the expression on the right-hand side using trigonometric identities. Let's start by expressing cos(x) in terms of sin(x):
cos(x) = √(1 - sin²(x))
Substituting this expression into the equation above:
sin(x) = √(1 - sin²(x)) × (m+n)/(m-n)
Squaring both sides and rearranging terms:
(m-n)² × sin²(x) = (m+n)² × (1 - sin²(x))
Expanding the terms on the right-hand side:
(m-n)² × sin²x) = (m+n)² - (m+n)² × sin²(x)
Simplifying and solving for sin(x):
sin(x) = (m+n) / √[(m+n)² + (m-n)²]
Now, to choose the answer choice that matches this expression. Simplify each of the answer choices:
(A) ((m+n)√2)/(2√m²+n²) = (m+n) / √[(m+n)² + (m-n)²]
(B) ((m+n)√2)/(2√m²-n²) ≠ (m+n) / √[(m+n)² + (m-n)²]
(C) ((m-n)√2)/(2√m²+n²) ≠ (m+n) / √[(m+n)² + (m-n)²]
(D) ((m-n)√2)/(2√m²-n²) ≠ (m+n) / √[(m+n)² + (m-n)²]
Therefore, the answer is (A) ((m+n)√2)/(2√m²+n²).
Find out more on tangents here: https://brainly.com/question/24305408
#SPJ1
If in a city of 1000 households, 100 are watching ABC, 80 are watching CBS, 50 are watching NBC, 70 are watching Fox, 500 are watching everything else, and 200 do not have the TV set on, what is CBS's share
Answers
CBS's share of households in the city is 8%.
Out of the 1000 households in the city:
100 are watching ABC
80 are watching CBS
50 are watching NBC
70 are watching Fox
500 are watching everything else
200 do not have the TV set on
To calculate CBS's share, we need to find the percentage of households that are watching CBS out of the total number of households:
CBS's share = (number of households watching CBS / total number of households) x 100%
CBS's share = (80 / 1000) x 100%
CBS's share = 8%
Therefore, CBS's share of households in the city is 8%.
for such more question on word problem
https://brainly.com/question/1781657
#SPJ11
If you were standing on the top floor of the Sears Tower in Chicago, how much higher would you be than if you were standing on the top floor of the Petronas Towers in Kuala Lumpur
Answers
So you would be about 33 feet (10 meters) higher if you were standing on the top floor of the Petronas Towers compared to the top floor of the Sears Tower.
The Sears Tower, now known as the Willis Tower, has a height of 1,450 feet (442 meters) to the top of its roof, or 1,729 feet (527 meters) including its antennas. The Petronas Towers, on the other hand, have a height of 1,483 feet (452 meters) to the top of their spires. Therefore, if you were standing on the top floor of the Sears Tower in Chicago, you would be lower than if you were standing on the top floor of the Petronas Towers in Kuala Lumpur, since the Petronas Towers are taller. The height difference between the two buildings would be:1,483 ft (452 m) - 1,450 ft (442 m) = 33 ft (10 m)So you would be about 33 feet (10 meters) higher if you were standing on the top floor of the Petronas Towers compared to the top floor of the Sears Tower.
Learn more about Sears Tower.
https://brainly.com/question/4852159
#SPJ4
Create a question involving a real-world application that can be solved by
the sine or cosine law. Draw a triangle that represents the situation and
solve the triangle.
Answers
The sample question is: "Two trees, 70 meters apart, are connected by a 100-meter zip line. How high is the zip line linked to the tree if the elevation difference between the ground and the zip line is 30 degrees? Use the sine law to solve the triangle."
How to solveBy using the sine law, it is possible to calculate that sin(30°) = x/sin(150°)
Making use of above equation, we can determine that x = sin(30°) * sin(150°) / sin(180°), which gives us a value of 50m.
Therefore, the zip line must be attached to the tree at a height of around fifty meters.
Read more about sine law here:
https://brainly.com/question/20839703
#SPJ1
Average air pressure at sea level is about 14.7 pounds per square inch, and Earth's total surface area is about 197,000,000 square miles. One square mile equals 4,000,000,000 square inches. Using this information, how much does the entire atmosphere weigh
Answers
The average air pressure at sea level is approximately 14.7 pounds per square inch (psi). Earth's total surface area is about 197,000,000 square miles, and one square mile equals 4,000,000,000 square inches.
To determine the total weight of the atmosphere, we first need to calculate the total air pressure on Earth's surface.
First, we convert the total surface area from square miles to square inches:
197,000,000 square miles * 4,000,000,000 square inches/square mile = 7.88 x 10^17 square inches
Next, we multiply the total surface area in square inches by the average air pressure at sea level:
7.88 x 10^17 square inches * 14.7 psi = 1.158 x 10^19 pounds
Thus, the entire atmosphere weighs approximately 1.158 x 10^19 pounds. This massive weight is distributed evenly across Earth's surface, and it is the reason we experience atmospheric pressure.
The atmosphere's composition and its various layers play a vital role in sustaining life on Earth and maintaining a stable climate.
To learn more about total surface area click here
brainly.com/question/30991207
#SPJ11
A bag contains 4 red marbles, 3 blue marbles, and 7 green marbles. If a marble is randomly selected from the bag,
find the probability that a blue marble will be drawn.
Answers
Answer:
3/14
Step-by-step explanation:
The probability of drawing a blue marble can be found by dividing the number of blue marbles by the total number of marbles in the bag.
The total number of marbles in the bag is:
4 (red) + 3 (blue) + 7 (green) = 14
The number of blue marbles is 3.
So, the probability of drawing a blue marble is:
3/14
Answer:
Step-by-step explanation: d
Two random cards numbered from 1,2...100 are pulled from the deck. What is the probability that one number doubles the other from the deck
Answers
The probability that one number doubles the other from a deck of 1 to 100 numbered cards when two cards are drawn at random is 0.01 or 1%.
There are 100 cards in the deck numbered from 1 to 100, so there are 100 ways to choose the first card. For the second card, we have two cases to consider: either the second card is double the first or the first card is double the second.
If the first card is k, then the probability that the second card is 2k is 1/99, since there are 99 cards left in the deck and only one of them is 2k. Similarly, if the second card is k, then the probability that the first card is 2k is also 1/99.
Therefore, the probability that one number doubles the other is the sum of these probabilities, which is (100 * 1/99) * 2 = 2.02%. However, we have counted the case where the two cards are the same twice, so we need to subtract this probability (1/100) once, giving us a final probability of 2.02% - 1% = 1%.
To know more about probability , refer here:
https://brainly.com/question/31469353#
#SPJ11
3) Find the forward rate between the 3rd and 4th periods if you know that the 3 and 4 years spot rates are 4% and 5%
Answers
Therefore, The forward rate between the 3rd and 4th periods is approximately 8.07%.
To find the forward rate between the 3rd and 4th periods, we need to use the spot rates for 3 and 4 years. The formula to calculate the forward rate is:
Forward rate = ((1 + Spot rate for 4 years) ^ 4 / (1 + Spot rate for 3 years) ^ 3) - 1
Here, the 3-year spot rate is 4% (0.04), and the 4-year spot rate is 5% (0.05).
Step 1: Convert percentages to decimals and add 1:
(1 + 0.04) = 1.04 for 3-year spot rate
(1 + 0.05) = 1.05 for 4-year spot rate
Step 2: Raise the values to their respective years:
(1.04) ^ 3 = 1.124864
(1.05) ^ 4 = 1.21550625
Step 3: Divide the 4-year value by the 3-year value:
1.21550625 / 1.124864 = 1.08068
Step 4: Subtract 1 to get the forward rate:
1.08068 - 1 = 0.08068 (rounded)
Therefore, The forward rate between the 3rd and 4th periods is approximately 8.07%.
To know more about the rate visit:
https://brainly.com/question/119866
#SPJ11
Nick has 3 shirts: a white one, a black one, and a blue one. He also has two pairs of pants, one blue and one tan. What is the probability, if Nick gets dressed in the dark, that he winds up wearing the white shirt and tan pants
Answers
Answer: 1/6
Step-by-step explanation: if he has 3 shirts you multiply that by 2 which would make 6 and that would become the denominator and the white shirt matching out with the tan pants would be a probability of 1 as there are 6 different possibilities. The probability of 1 will also be the numerator