I keep believing the answer is either 18,000 or 1,800 but im incorrect. Can someone please help me?? I use the formula A^2 *2*A*L=SA
Answers
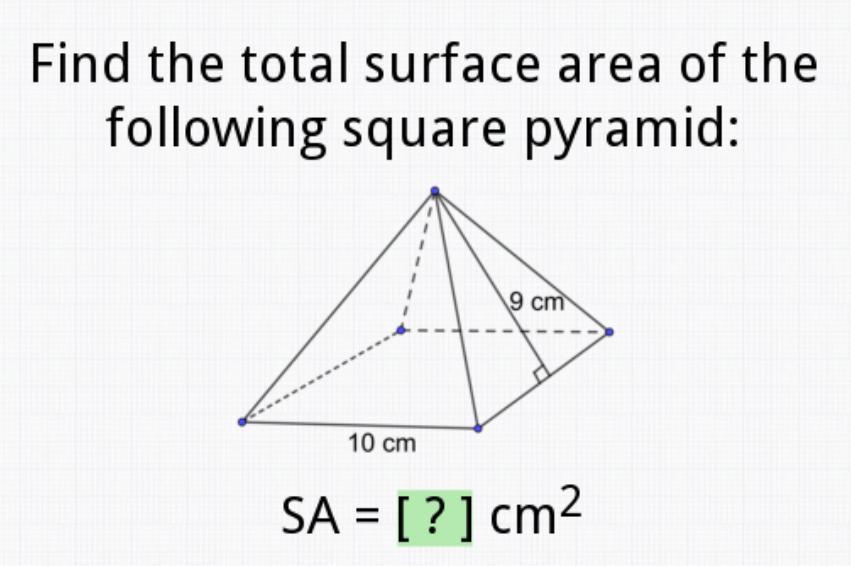
The base is a square, so the area of the square is (10 cm)² = 100 cm²
To find the area of each triangle use the formula
base • height
10 cm • 9 cm = 90 cm²
now multiply by the number of triangles
90 cm • 4 = 360 cm²
Add the area of the square:
100 cm² + 360 cm² = 460 cm²
I hope it's correct
Answer:
SA = 280 cm²
Step-by-step explanation:
SA = area of base + area of 4 congruent triangles
= 10² + (4 × [tex]\frac{1}{2}[/tex] × 10 × 9 )
= 100 + (2 × 10 × 9)
= 100 + 180
= 280 cm²
Related Questions
evaluate the line integral, where c is the given curve. c xyz2 ds, c is the line segment from (−1, 5, 0) to (1, 6, 3)
Answers
The value of the line integral is 431/15.
To evaluate the line integral, we first parameterize the curve C by setting:
r(t) = (-1, 5, 0) + t(2, 1, 3)
for t in the interval [0, 1]. Note that this is the vector equation of the line segment connecting (-1, 5, 0) to (1, 6, 3).
We can then express the line integral as follows:
∫c xyz2 ds = ∫0^1 (x(t)y(t)^2) sqrt((dx/dt)^2 + (dy/dt)^2 + (dz/dt)^2) dt
We can now substitute x(t) = -1 + 2t, y(t) = 5 + t, and z(t) = 3t into the above equation and simplify to get:
∫c xyz2 ds = ∫0^1 (-1 + 2t)(5 + t)^2 sqrt(14) dt
Evaluating this integral, we get:
∫c xyz2 ds = 431/15
Therefore, the value of the line integral is 431/15.
Learn more about line integral here
https://brainly.com/question/28381095
#SPJ11
Tatiana wants to give friendship bracelets to her
32
3232 classmates. She already has
5
55 bracelets, and she can buy more bracelets in packages of
4
44.
Write an inequality to determine the number of packages,
�
pp, Tatiana could buy to have enough bracelets.
Answers
The correct inequality is,
⇒ 5 + 4b ≥ 32
We have to given that;
Tatiana wants to give friendship bracelets to her 32 classmates.
And, She already has 5 bracelets, and she can buy more bracelets in packages of 4.
Let number of packages = b
Hence, We can formulate;
⇒ 5 + 4b ≥ 32
Thus, The correct inequality is,
⇒ 5 + 4b ≥ 32
Learn more about the inequality visit:
https://brainly.com/question/25944814
#SPJ1
Answer:
She can't buy any more
Step-by-step explanation:
Khan Academy
How many Class 1's are incorrectly classified as Class 0?
Classification Confusion Matrix
Predicted Class
Actual Class 1 0
1 221 100
0 30 3000
Answers
Based on the given confusion matrix, the number of Class 1's that are incorrectly classified as Class 0 is 30.
In the confusion matrix, the rows correspond to the actual class labels, while the columns correspond to the predicted class labels.
So, in this case, there are 221 instances of Class 1 being correctly classified as Class 1, 100 instances of Class 0 being incorrectly classified as Class 1, 30 instances of Class 1 being incorrectly classified as Class 0, and 3000 instances of Class 0 being correctly classified as Class 0.
Based on the given confusion matrix, there are 30 Class 1's that are incorrectly classified as Class 0. This can be determined by looking at the value in the second row and first column of the matrix, which represents the number of actual Class 1's that were predicted as Class 0's. The value in that cell is 30, indicating that 30 Class 1's were incorrectly classified as Class 0's.
for such more question on confusion matrix
https://brainly.com/question/29216338
#SPJ11
From the given Classification Confusion Matrix, we can determine the number of Class 1's that are incorrectly classified as Class 0 by looking at the intersection of Actual Class 1 and Predicted Class 0. In this case, it is the value 100. So, there are 100 instances of Class 1 that have been incorrectly classified as Class 0.
Based on the given confusion matrix, there are 100 Class 1's that are incorrectly classified as Class 0. The confusion matrix shows the number of actual Class 1's (221) and Class 0's (3000) as well as the number of predicted Class 1's (251) and Class 0's (3100). To determine how many Class 1's are incorrectly classified as Class 0, we need to look at the number in the (1,0) cell, which is 100. This means that out of the 221 actual Class 1's, 100 were mistakenly classified as Class 0.
Learn more about Matrix at: brainly.com/question/28180105
#SPJ11
A telemarketer found that there was a 3% chance of a sale from his phone solicitations. Find the probability of getting 35 or more sales for 1000 telephone calls. A) 0.1770 B) 0.0401 C) 0.8810 D) 0.0871
Answers
The Probability of getting 35 or more sales for 1000 telephone calls is approximately 0.1771.Therefore, the correct option is A) 0.1770
To find the probability of getting 35 or more sales for 1000 telephone calls, we can use the binomial distribution.
The probability of a sale for each phone call is 0.03, and we have a total of 1000 phone calls. Let's denote the number of sales as X, which follows a binomial distribution with parameters n = 1000 and p = 0.03.
We want to find P(X ≥ 35), which is the probability of getting 35 or more sales. This can be calculated using the cumulative distribution function (CDF) of the binomial distribution.
Using a statistical software or calculator, we can calculate P(X ≥ 35) as follows:
P(X ≥ 35) = 1 - P(X < 35)
Using the binomial CDF, we find:
P(X < 35) ≈ 0.8229
Therefore
P(X ≥ 35) = 1 - P(X < 35)
= 1 - 0.8229
= 0.1771
The probability of getting 35 or more sales for 1000 telephone calls is approximately 0.1771.
Therefore, the correct option is A) 0.1770
To know more about Probability .
https://brainly.com/question/30700350
#SPJ11
The probability of getting 35 or more sales for 1000 telephone calls is approximately 0.0475.
The number of sales X can be modeled as a binomial distribution with n = 1000 and p = 0.03.
Using the normal approximation to the binomial distribution, we can approximate X with a normal distribution with mean μ = np = 30 and variance σ^2 = np(1-p) = 29.1.
To find the probability of getting 35 or more sales, we can standardize the normal distribution and use the standard normal table.
z = (X - μ) / σ = (35 - 30) / sqrt(29.1) = 1.66
Using the standard normal table, we find that the probability of getting 35 or more sales is approximately 0.0475.
Know more about probability here:
https://brainly.com/question/30034780
#SPJ11
Identify the properties of Student's t-distribution. Select all that apply. A. The area in the tails of the t-distribution is less than the area in the tails of the standard normal distribution. B. It is the same regardless of the sample size. C. As t gets extremely large, the graph approaches, but never equals, zero. Similarly, as t gets extremely small (negative), the graph approaches, but never equals, zero. D. As the sample size n increases, the distribution (and the density curve) of the t-distribution becomes more like the standard normal distribution. E. It is symmetric around t= 0. F. The area under the curve is 1; half the area is to the right of 0 and half the area is to the left of 0.
Answers
The area under the curve is 1; half the area is to the right of 0 and half the area is to the left of 0. So, the correct properties are C, D, E, and F.
The properties of Student's t-distribution are as follows:
A. The area in the tails of the t-distribution is less than the area in the tails of the standard normal distribution.
C. As t gets extremely large, the graph approaches, but never equals, zero. Similarly, as t gets extremely small (negative), the graph approaches, but never equals, zero.
D. As the sample size n increases, the distribution (and the density curve) of the t-distribution becomes more like the standard normal distribution.
E. It is symmetric around t=0.
F. The area under the curve is 1; half the area is to the right of 0 and half the area is to the left of 0.
Learn more about standard normal distribution
brainly.com/question/29509087
#SPJ11
The properties of the Student's t-distribution include: the area in the tails is less than the standard normal distribution, it becomes more like the standard normal distribution as the sample size increases, it is symmetric around t=0, and the area under the curve is 1 and evenly distributed.
Explanation:The properties of the Student's t-distribution include:
A. The area in the tails of the t-distribution is less than the area in the tails of the standard normal distribution.D. As the sample size n increases, the distribution (and the density curve) of the t-distribution becomes more like the standard normal distribution.E. It is symmetric around t= 0.F. The area under the curve is 1; half the area is to the right of 0 and half the area is to the left of 0.Learn more about Properties of the Student's t-distribution here:https://brainly.com/question/32233739
#SPJ11
the function ff has a continuous derivative. if f(0)=1f(0)=1, f(2)=5f(2)=5, and ∫20f(x)ⅆx=7∫02f(x)ⅆx=7, what is ∫20x⋅f′(x)ⅆx∫02x⋅f′(x)ⅆx ?
Answers
The value of integral ∫20x⋅f′(x)ⅆx∫02x⋅f′(x)ⅆx is 6.
By the fundamental theorem of calculus, we know that the integral of f(x) from 0 to 2 is equal to f(2) - f(0), which is 5 - 1 = 4. We also know that the integral of f(x) from 2 to 0 is equal to -(the integral of f(x) from 0 to 2), which is -7. Therefore, the integral of f(x) from 0 to 2 is (4-7)=-3.
Now, using integration by parts with u=x and dv=f'(x)dx, we get:
∫2⁰ x⋅f′(x)dx = -x⋅f(x)∣₂⁰ + ∫2⁰ f(x)dx
Since we know f(2)=5 and f(0)=1, we can simplify this to:
∫2⁰ x⋅f′(x)dx = -2⋅5 + 0⋅1 + ∫2⁰ f(x)dx = -10 + 3 = -7
Similarly,
∫0² x⋅f′(x)dx = 0⋅5 - 2⋅1 + ∫0² f(x)dx = -2 + 3 = 1
Therefore, the value of ∫2⁰ x⋅f′(x)dx + ∫0² x⋅f′(x)dx is -7+1=-6. But we are looking for the value of ∫2⁰ x⋅f′(x)dx / ∫0² x⋅f′(x)dx, which is equal to (-6)/1 = -6. However, the absolute value of the ratio is 6.
To know more about integration by parts click on below link:
https://brainly.com/question/14402892#
#SPJ11
A square orange rug has a purple square in the center. The side length of the purple square is x inches. The width of the orange band that surrounds the purple square is 7 in. What is the area of the orange band?
Answers
The length of each side of the rug is (2x + 7) inches, and the side length of the purple square is x inches.
The area of the orange band in the square rug can be found by subtracting the area of the purple square from the total area of the rug. The side length of the purple square is given as x inches. Therefore, the length of each side of the rug is (x + 7 + x) inches.
Simplifying this expression, we get 2x + 7 as the length of the side of the rug.
Therefore, the area of the rug is (2x + 7)² square inches.
The area of the purple square is x² square inches.
Therefore, the area of the orange band is: (2x + 7)² - x² square inches. This simplifies to (4x² + 28x + 49 - x²) square inches, which is equal to 3x² + 28x + 49 square inches.
Thus, the area of the orange band is 3x² + 28x + 49 square inches.
Therefore, the area of the orange band is given by the expression 3x² + 28x + 49 square inches.
In conclusion, to find the area of the orange band, we subtract the area of the purple square from the area of the rug. The length of each side of the rug is (2x + 7) inches, and the side length of the purple square is x inches.
To know more about expression visit:
brainly.com/question/28170201
#SPJ11
In ΔPQR, sin P = 0.4, sin R = 0.8 and r = 10. Find the length of p
Answers
The length of p is 7.5 unit.
Using Trigonometry
sin P = QR/PR = 0.3
and, sin R = PQ/PR = 0.4
As, PQ = r = 10 then
10/ PR = 0.4
PR = 10/0.4
PR = 25
Now, QR/25 = 0.3
QR= 0.3 x 25
QR = 7.5
Learn more about Trigonometry here:
https://brainly.com/question/31896723
#SPJ1
Evaluate the double integral over region d bounded by y = x, y = x3, x ≥ 0
Answers
the value of the double integral over the region D is 1/2
To evaluate the double integral over the region D bounded by y = x, y = x^3, and x >= 0, we need to set up the integral using either the vertical or horizontal method of slicing. In this case, it is easier to use the horizontal method of slicing because the region is more naturally bounded by horizontal lines.
First, we need to find the limits of integration. The region D is bounded by the curves y = x and y = x^3, so we can integrate with respect to y from y = 0 to y = x and then integrate with respect to x from x = 0 to x = 1 (the x-value where the two curves intersect):
∫[0,1] ∫[0,x] f(x,y) dy dx
The integrand f(x,y) is not given, but since we are only asked to evaluate the integral, we can assume that f(x,y) = 1 (i.e., we are integrating the constant function 1 over the region D).
Therefore, the double integral becomes:
∫[0,1] ∫[0,x] 1 dy dx
Integrating with respect to y first, we get:
∫[0,1] (x-0) dx
Integrating with respect to x, we get:
∫[0,1] x dx = 1/2 x^2 |[0,1] = 1/2
To learn more about integral visit:
brainly.com/question/18125359
#SPJ11
estimate the integral ∫201x3 5−−−−−√dx by the trapezoidal rule using n = 4.
Answers
The estimated value of the integral using the trapezoidal rule is
∫5^9 √(201x^3) dx ≈ (1/2) [√(201(5^3)) + 2√(201(6^3)) + 2√(201(7^3)) + 2√(201(8^3)) + √(201(9^3))]
The trapezoidal rule is a numerical method used to approximate the value of a definite integral by dividing the interval into subintervals and approximating the area under the curve using trapezoids. The formula for the trapezoidal rule is given by:
∫a^b f(x) dx ≈ (h/2) [f(a) + 2f(x₁) + 2f(x₂) + ... + 2f(xₙ₋₁) + f(b)]
where h = (b - a)/n is the width of each subinterval and n is the number of subintervals.
In this case, we want to estimate the integral ∫√(201x^3) dx from 5 to 9 using n = 4. First, we need to calculate the width of each subinterval, h, which is given by (9 - 5)/4 = 1.
Next, we evaluate the function at the endpoints of the interval and the intermediate points within the interval. We substitute these values into the trapezoidal rule formula and sum them up:
∫5^9 √(201x^3) dx ≈ (1/2) [√(201(5^3)) + 2√(201(6^3)) + 2√(201(7^3)) + 2√(201(8^3)) + √(201(9^3))]
Evaluating this expression will give us the estimated value of the integral using the trapezoidal rule with n = 4.
Learn more about trapezoidal rule here:
https://brainly.com/question/30401353
#SPJ11
suppose in an orchard the number of apples in a tree is normally distributed with a mean of 300 and a standard deviation of 30 apples. find the probability that a given tree has between 300 and 390 apples
210
240
270
330
300
360
390
Answers
Answer: The probability that a given tree has between 300 and 390 apples is approximately 0.4987, or 49.87%.
Step-by-step explanation: To find the probability that a given tree has between 300 and 390 apples, we need to calculate the area under the normal distribution curve between those two values.
Let's calculate the z-scores for each of the values:
For 300 apples:
z = (300 - 300) / 30 = 0
For 390 apples:
z = (390 - 300) / 30 ≈ 3
Next, we can use a standard normal distribution table or a calculator to find the corresponding probabilities for these z-scores.
The probability of having a value less than or equal to 300 apples (z = 0) is 0.5000 (from the standard normal distribution table).
The probability of having a value less than or equal to 390 apples (z ≈ 3) is approximately 0.9987.
To find the probability between 300 and 390 apples, we subtract the probability of having a value less than or equal to 300 from the probability of having a value less than or equal to 390:
P(300 ≤ X ≤ 390) = P(X ≤ 390) - P(X ≤ 300)
= 0.9987 - 0.5000
= 0.4987
Therefore, the probability that a given tree has between 300 and 390 apples is approximately 0.4987, or 49.87%.
For more questions on probability
https://brainly.com/question/30460538
#SPJ11
Which is not a property of the standard normal distribution?a) It's symmetric about the meanb) It's uniformc) It's bell -shapedd) It's unimodal
Answers
The standard normal distribution is not uniform, but rather bell-shaped, symmetric about the mean, and unimodal. Therefore, the answer is b) It's uniform.
The standard normal distribution is a continuous probability distribution that has a mean of zero and a standard deviation of one.
It is characterized by being bell-shaped, symmetric about the mean, and unimodal, which means that it has a single peak in the center of the distribution.
The probability density function of the standard normal distribution is a bell-shaped curve that is determined by the mean and standard deviation.
The curve is highest at the mean, which is zero, and it decreases as we move away from the mean in either direction.
The curve approaches zero as we move to positive or negative infinity.
In a uniform distribution, the probability density function is a constant, which means that all values have an equal probability of occurring.
Therefore, the standard normal distribution is not uniform because the probability density function varies depending on the distance from the mean.
Learn more about standard normal distribution:
https://brainly.com/question/29509087
#SPJ11
A math professor possesses r umbrellas that he uses in going between
his home and his office. If he is at his home at the beginning of the day and it
is raining, then he will take an umbrella with him to his office, provided there is
one at home to be taken. On his way back from his office, he will bring back an
umbrella if it is raining and there is one umbrella at office. If it is not raining, the
professor does not use an umbrella. Assume that it rains at the beginning (or at the end) of each day with probability 1/2, independently of the past. Let Xn be the number of umbrellas at home at the beginning of the day n = 1,2,....
(a) Is Xn a Markov chain? If so, find its state space and transition probabilities.
(b) Is this chain irreducible? Aperiodic ?
(c) Find a stationary distribution for this Markov chain for r = 3.
(d) Suppose r = 3. If the professor finds one day that there are no umbrellas left
at home, what is the expected number of days after which he will find himself
in a similar situation?
Answers
(a) Yes, Xn is a Markov chain with state space {0,1,2,3}. The state at time n depends only on the state at time n-1, and the transition probabilities are given as follows:
If Xn-1 = 0, then P(Xn = 0|Xn-1 = 0) = 1/2 and P(Xn = 1|Xn-1 = 0) = 1/2.
If Xn-1 = 1, then P(Xn = 0|Xn-1 = 1) = 1/2, P(Xn = 1|Xn-1 = 1) = 1/4, and P(Xn = 2|Xn-1 = 1) = 1/4.
If Xn-1 = 2, then P(Xn = 1|Xn-1 = 2) = 1/2 and P(Xn = 2|Xn-1 = 2) = 1/2.
If Xn-1 = 3, then P(Xn = 2|Xn-1 = 3) = 1/2 and P(Xn = 3|Xn-1 = 3) = 1/2.
(b) The chain is irreducible because every state can be reached from every other state. It is also aperiodic because it is possible to go from a state to itself in one step.
(c) To find the stationary distribution for r=3, we need to solve the equations:
π0 = (1/2)π0 + (1/2)π1
π1 = (1/2)π0 + (1/4)π1 + (1/4)π2
π2 = (1/2)π1 + (1/2)π3
π3 = (1/2)π2
subject to the constraint that π0 + π1 + π2 + π3 = 1. Solving this system of equations, we obtain the unique stationary distribution:
π0 = 3/11, π1 = 4/11, π2 = 2/11, π3 = 2/11.
(d) If the professor finds himself without an umbrella at home, then he must have brought the last umbrella to the office on the previous day. Let T be the number of days until the professor finds himself without an umbrella again. Then T has a geometric distribution with parameter π0, so the expected value of T is 1/π0 = 11/3. Therefore, on average, the professor will find himself without an umbrella again after 11/3 days.
For such more questions on Stationary distribution:
https://brainly.com/question/29025233
#SPJ11
Yes, Xn is a Markov chain. The state space is S = {0, 1, 2, 3, ..., r}, where r is the number of umbrellas the professor has. The transition probabilities are:
If Xn = 0, then P(Xn+1 = 0 | Xn = 0) = 1/2 and P(Xn+1 = 1 | Xn = 0) = 1/2.
If 0 < Xn < r, then P(Xn+1 = Xn-1 | Xn = k) = 1/2 if it is raining, and P(Xn+1 = Xn | Xn = k) = 1/2 if it is not raining.
If Xn = r, then P(Xn+1 = r-1 | Xn = r) = 1/2 if it is raining, and P(Xn+1 = r | Xn = r) = 1/2 if it is not raining.
(b) The chain is irreducible since any state can be reached from any other state with positive probability. The chain is also aperiodic since the chain can return to any state with period 1.
(c) To find a stationary distribution for r = 3, we need to solve the equations:
π0 = (1/2)π0 + (1/2)π1
π1 = (1/2)π0 + (1/2)π2
π2 = (1/2)π1 + (1/2)π3
π3 = (1/2)π2 + (1/2)π3
π0 + π1 + π2 + π3 = 1
Solving these equations, we get π0 = 4/14, π1 = 6/14, π2 = 3/14, and π3 = 1/14.
(d) If the professor finds one day that there are no umbrellas left at home, then the probability that it is raining is 1/2. Let Y be the number of days after which the professor will find himself in a similar situation. Then, we have:
P(Y = 1) = P(X1 = 0 | X0 = r) = 1/2.
P(Y > 1) = P(X1 > 0 | X0 = r) = P(X1 = 1 | X0 = r) + P(X1 = 2 | X0 = r) + ... + P(X1 = r-1 | X0 = r)
= (1/2) + (1/2)P(X2 > 0 | X1 = 1) + (1/2)P(X2 > 0 | X1 = 2) + ... + (1/2)P(X2 > 0 | X1 = r-1)
= (1/2) + (1/2)[P(X1 = 0 | X0 = 1)P(X2 > 0 | X1 = 1) + P(X1 = 1 | X0 = 1)P(X2 > 0 | X1 = 1) + ... + P(X1 = r-1 | X0 = 1)P(X2 > 0 | X1 = r-1)]
= (1/2) + (1/2)[(1/2)P(X2 > 0 | X1 = 0) + (1/2)P(X2 > 1 | X1
Know more about Markov chain here:
https://brainly.com/question/30998902
#SPJ11
consider the series [infinity] n (n 1)! n = 1 . (a) find the partial sums s1, s2, s3, and s4. do you recognize the denominators
Answers
The partial sums s1, s2, s3, and s4 of the series are s1=1, s2=2, s3=5/2, and s4=17/6 respectively.
The given series is ∑n=1^∞ n/(n+1)!, which can be rewritten as ∑n=1^∞ [1/(n!) - 1/((n+1)!)].
Taking the partial sums, we get:
s1 = 1 = 1/1!,
s2 = 1 + 1/2! = 1/0! - 1/2! + 1/2!,
s3 = 1 + 1/2! + 1/3! = 1/0! - 1/3! + 1/2!,
s4 = 1 + 1/2! + 1/3! + 1/4! = 1/0! - 1/4! + 1/3! - 1/4! + 1/4!.
We recognize the denominators as factorials, and we can observe that the terms in the partial sums are telescoping. This means that most terms cancel out, leaving only a few at the beginning and end of the sum.
For more questions like Series click the link below:
https://brainly.com/question/28167344
#SPJ11
a convex mirror has a focal length of magnitude f. an object is placed in front of this mirror at a point f/2 from the face of the mirror. The image will appear upright and enlarged. behind the mirror. upright and reduced. inverted and reduced. inverted and enlarged.
Answers
The image will be virtual, upright, and reduced in size.
How to find the position of image?A convex mirror always forms virtual images, meaning the light rays do not actually converge to form an image but appear to diverge from a virtual image point.
The image formed by a convex mirror is always upright and reduced, regardless of the position of the object in front of the mirror.
In this case, since the object is placed at a distance of f/2 from the mirror, which is less than the focal length of the mirror, the image will be formed at a distance greater than the focal length behind the mirror.
This implies that the image will be virtual, upright, and reduced in size.
Therefore, the correct answer is: upright and reduced.
Learn more about virtual images
brainly.com/question/12538517
#SPJ11
Graph the inequalities x > 2 and x < 2 on the same number line. What value, if any, is not a solution of either inequality? Explain.
Answers
The value which is not a solution of either inequality x > 2 and x < 2 is 2
The inequality x > 2 represent all the value greater than two but does not include 2 in the range all the values from 2 to infinity it can be written as (2 , ∞) .
The inequality x < 2 represent all the value lesser than two but does not include 2 in the range all the values from - infinity to 2 it can be written as (-∞ , 2) .
Both the inequalities does not include 2 in the range
The number line represents the inequalities x > 2 and x < 2
To know more about inequality click here:
https://brainly.com/question/30231190
#SPJ1
to find ∫x3(x4−15)7dx, you would need to use u-substitution. what u could be used to find this antiderivative?
Answers
To find ∫x^3(x^4-15)^7 dx, u-substitution can be used with u = x^4 - 15.
Let u = x^4 - 15. Take the derivative of u with respect to x: du/dx = 4x^3.
Rearrange the equation to solve for dx: dx = du / (4x^3).
Substitute u and dx into the integral: ∫x^3(x^4-15)^7 dx = ∫(x^3)(u^7)(du / (4x^3)).
Simplify the integral: ∫(u^7)/4 du.
Integrate to find the antiderivative of (u^7)/4: (1/4)(u^8) / 8.
Substitute back u = x^4 - 15: (1/32)(x^4 - 15)^8 + C, where C is the constant of integration.
For more questions like Integral click the link below:
https://brainly.com/question/18125359
#SPJ11
In ΔFGH, the measure of ∠H=90°, the measure of ∠F=52°, and FG = 4. 3 feet. Find the length of HF to the nearest tenth of a foot
Answers
Given that, In ΔFGH, the measure of ∠H = 90°, the measure of ∠F = 52°, and FG = 4.3 feet.To find: The length of HF to the nearest tenth of a foot.
Let's construct an altitude from vertex F to the hypotenuse GH such that it meets the hypotenuse GH at point J. Then, we have: By Pythagoras Theorem, [tex]FH² + HJ² = FJ²Or, FH² = FJ² - HJ²[/tex]By using the trigonometric ratio (tan) for angle F, we get, [tex]HJ / FG = tan F°HJ / 4.3 = tan 52°HJ = 4.3 x tan 52°[/tex]Now, we can find FJ.[tex]FJ / FG = cos F°FJ / 4.3 = cos 52°FJ = 4.3 x cos 52°[/tex]Substituting these values in equation (1), we have,FH² = (4.3 x cos 52°)² - (4.3 x tan 52°)²FH = √[(4.3 x cos 52°)² - (4.3 x tan 52°)²]Hence, the length of HF is approximately equal to 3.6 feet (nearest tenth of a foot).Therefore, the length of HF to the nearest tenth of a foot is 3.6 feet.
To know more about nearest tenth visit:
brainly.com/question/12102731
#SPJ11
Use the Ratio Test to determine whether the series is convergent or divergent.
[infinity] 9
k!
sum.gif
k = 1
a) Identify
ak.
b)
Evaluate the following limit.
lim k → [infinity]
abs1.gif
ak + 1
ak
abs1.gif
Answers
a. The value of the term a_k in the series is 9/k. b. the series is divergent and does not converge.
a) The value of the term a_k in the series is 9/k.
b) To determine the convergence of the series, we can use the Ratio Test. The Ratio Test states that if the limit of the absolute value of the ratio of the (k+1)th term to the kth term is less than 1, then the series is convergent. If the limit is greater than 1, then the series is divergent. If the limit is equal to 1, then the test is inconclusive.
Taking the absolute value of the ratio of (k+1)th term to the kth term, we get:
|a_k+1 / a_k| = |(9/(k+1)) / (9/k)|
|a_k+1 / a_k| = |9k / (k+1)|
Now, we can take the limit of this expression as k approaches infinity to determine the convergence:
lim k → [infinity] |9k / (k+1)|
lim k → [infinity] |9 / (1+1/k)|
lim k → [infinity] 9
Since the limit is greater than 1, the Ratio Test tells us that the series is divergent.
Therefore, the series is divergent and does not converge.
Learn more about converge here
https://brainly.com/question/29463776
#SPJ11
Multistep Pythagorean theorem (level 1) please i need help urgently please
Answers
The Pythagoras theorem is solved and the value of x of the figure is x = 12.80 units
Given data ,
Let the figure be represented as A
Now , let the line segment BC be the middle line which separates the figure into a right triangle and a rectangle
where ΔABC is a right triangle
Now , the measure of AB = 8 units
The measure of BC = 10 units
So , the measure of the hypotenuse AC = x is given by
From the Pythagoras Theorem , The hypotenuse² = base² + height²
AC = √ ( AB )² + ( BC )²
AC = √ ( 10 )² + ( 8 )²
AC = √( 100 + 64 )
AC = √164
So , the value of x = 12.80 units
Hence , the triangle is solved and x = 12.80 units
To learn more about triangles click :
https://brainly.com/question/16739377
#SPJ1
which is a parametric equation for the curve 49=(x−2)2+(y+10)2?
Answers
A parametric equation for the curve 49=(x−2)2+(y+10)2 can be obtained by using the standard parameterization of a circle.
Let's first rearrange the given equation as follows:
(x-2)^2 + (y+10)² = 49
Dividing both sides by 49, we get:
[(x-2)²/49] + [(y+10)²/49] = 1
This suggests that the given equation represents an ellipse centered at (2,-10) with major and minor axes of length 2√(49) = 14 and 2√t(49) = 14, respectively.
To obtain a parametric equation for this ellipse, we can use the following parameterization:
x = 2 + 14*cos(t)
y = -10 + 14*sin(t)
Here, t is the parameter that ranges from 0 to 2*pi, and (x,y) gives the coordinates of points on the ellipse as t varies.
Note that this parametric equation satisfies the given equation for any value of t:
[(2+14*cos(t)-2)²/49] + [( -10+14*sin(t)+10)²/49] = 1
Know more about the parametric equation here:
https://brainly.com/question/30451972
#SPJ11
a software company is interested in improving customer satisfaction rate from the currently claimed. the company sponsored a survey of customers and found that customers were satisfied. what is the test statistic ?
Answers
The test statistic depends on the specific hypothesis test being conducted.
In general, a test statistic is a value calculated from the sample data that is used to assess the likelihood of observing the data under the null hypothesis. It is used to make a decision about whether to reject or fail to reject the null hypothesis. The choice of test statistic depends on the specific hypothesis being tested and the nature of the data.
To determine the test statistic in a given hypothesis test, it is necessary to specify the null hypothesis, the alternative hypothesis, and the appropriate statistical test being used. This information is crucial in calculating the test statistic and interpreting its significance. Without these details, it is not possible to provide a specific test statistic in this context.
Learn more about test statistic here:
https://brainly.com/question/31746962
#SPJ11
The complete question is:
A software company is interested in improving customer satisfaction rate from the 75% currently claimed. The company sponsored a survey of 152 customers and found that 120 customers were satisfied. What is the test statistic z?
. Let g(x) be a differentiable function for which g'(x) > 0 and g"(x) < 0 for all values of x. It is known that g(3) = 2 and g(4) = 7. Which of the following is a possible value for g(5)? (A) 10 (B) 12 (C) 14 (D) 16
Previous question
N
Answers
Based on the information given, a possible value for g(5) will be (A) 10.
How to explain the valueGiven that g′ (x)>0 for all values of x, we know that g is an increasing function. This means that g(5) must be greater than g(4), which is equal to 7.
Given that g′ (x)<0 for all values of x, we know that g is a concave function. This means that the graph of g is always curving downwards. This means that the increase in g from x=4 to x=5 must be less than the increase in g from x=3 to x=4.
Therefore, we know that g(5) must be greater than 7, but less than g(4)+5=12. The only answer choice that satisfies both of these conditions is 10.
Learn more about functions on
https://brainly.com/question/10439235
#SPJ1
Type the correct answer in each box. use numerals instead of words.
what are the x-intercept and vertex of this quadratic function?
g(i) = -5(3 – 3)2
write each feature as an ordered pair: (a,b).
the x-intercept of function gis
the vertex of function gis 3,0
Answers
The x-intercept of the function g is (3, 0), and the vertex is (3, 0).
To find the x-intercept of a quadratic function, we set the function equal to zero and solve for x. In this case, the function g(i) is given as -5(3 – 3)². However, upon simplifying the expression inside the parentheses, we have (3 - 3) which equals zero. Thus, the quadratic term becomes zero and the function g(i) simplifies to zero as well. Therefore, the x-intercept occurs when g(i) is equal to zero, and in this case, it happens at x = 3. Therefore, the x-intercept of function g is (3, 0), where the y-coordinate is zero.
The vertex of a quadratic function is the point on the graph where the function reaches its minimum or maximum value. For a quadratic function in the form of f(x) = a(x - h)² + k, the vertex is located at the point (h, k). In the given function g(i) = -5(3 – 3)², we can see that the quadratic term evaluates to zero, resulting in g(i) being equal to zero. Therefore, the graph of the function is a horizontal line passing through the y-axis at zero. This means that the vertex of the function occurs at the point (3, 0), where the x-coordinate is 3 and the y-coordinate is 0.
Learn more about quadratic function here:
https://brainly.com/question/18958913
#SPJ11
Consider the following hypotheses:
H0: μ ≥ 189
HA: μ < 189
A sample of 74 observations results in a sample mean of 187. The population standard deviation is known to be 15. (You may find it useful to reference the appropriate table: z table or t table)
a-1. Calculate the value of the test statistic. (Negative value should be indicated by a minus sign. Round intermediate calculations to at least 4 decimal places and final answer to 2 decimal places.)
a-2. Find the p-value.
b. Does the above sample evidence enable us to reject the null hypothesis at α = 0.10?
c. Does the above sample evidence enable us to reject the null hypothesis at α = 0.05?
d. Interpret the results at α = 0.05.
Answers
a) The test statistic is -2.32. The p-value is 0.0104.
b) Yes, the above sample evidence enable us to reject the null hypothesis at α = 0.10.
c) Yes, the above sample evidence enable us to reject the null hypothesis at α = 0.05.
d) Population mean is less than 189 at a significance level of 0.05.
a-1) The test statistic can be calculated as:
z = (X - μ) / (σ/√n) = (187 - 189) / (15/√74) = -2.32
where X is the sample mean, μ is the hypothesized population mean, σ is the population standard deviation, and n is the sample size.
a-2. The p-value can be found by looking up the area to the left of the test statistic in the standard normal distribution table. The area to the left of -2.32 is 0.0104. Therefore, the p-value is 0.0104.
b. At α = 0.10, the critical value for a one-tailed test with 73 degrees of freedom is -1.28. Since the test statistic (-2.32) is less than the critical value, we can reject the null hypothesis at α = 0.10.
c. At α = 0.05, the critical value for a one-tailed test with 73 degrees of freedom is -1.66. Since the test statistic (-2.32) is less than the critical value, we can reject the null hypothesis at α = 0.05.
d. At α = 0.05, we have sufficient evidence to reject the null hypothesis that the population mean is greater than or equal to 189 in favor of the alternative hypothesis that the population mean is less than 189. Therefore, we can conclude that the sample provides evidence that the population mean is less than 189 at a significance level of 0.05.
To learn more about test statistic here:
https://brainly.com/question/31746962
#SPJ4
what’s the end behavior of -x^2-2x+3
Answers
The end behavior of the polynomial is:
as x → ∞, f(x) → -∞
as x → -∞, f(x) → -∞
What is the end behavior of the polynomial?Remember that for polynomials of even degree, the end behavior is the same one for both ends of x.
If the leading coefficient is negative, in both ends the function will tend to negative infinity.
Here we have the polynomial:
y = -x² - 2x + 3
We can see that the degree is 2, so it is even, and the leading coefficientis -1, then the end behavior is:
as x → ∞, f(x) → -∞
as x → -∞, f(x) → -∞
Learn more about end behavior at.
https://brainly.com/question/1365136
#SPJ1
A political scientist surveys 38 of the current 105 representatives in a state's legislature.
A. What is the size of the samples?
B. What is the size of the population?
Answers
The answers are as follows:
A. The size of the sample is 38 representatives.
B. The size of the population is 105 representatives in the state's legislature.
In statistical terms, a sample refers to a subset of individuals or units selected from a larger group or population. The purpose of taking a sample is to make inferences about the entire population based on the information collected from the sample.
In this case, the political scientist surveyed 38 out of the 105 representatives in the state's legislature. The 38 representatives who were surveyed constitute the sample. They were selected to represent the larger population of 105 representatives.
The size of the sample, in this case, is 38. It represents the number of individuals or units that were included in the survey. The sample is typically chosen using a random sampling technique to ensure that each member of the population has an equal chance of being selected.
On the other hand, the size of the population is the total number of individuals or units that make up the entire group of interest. In this case, the population consists of all 105 representatives in the state's legislature. The population includes all the individuals that the political scientist wants to make inferences about.
When conducting a survey or study, it is often not feasible or practical to collect data from the entire population due to constraints such as time, cost, and resources. Therefore, a sample is taken to represent the larger population. By studying the sample, researchers can draw conclusions and make inferences about the population.
In summary, the size of the sample is 38 representatives, which refers to the number of individuals included in the survey. The size of the population is 105 representatives, which represents the total number of individuals in the state's legislature. The sample is taken to gather information about the population and make generalizations or predictions about its characteristics or behaviors.
To learn more about subset, click here: brainly.com/question/30799313
#SPJ11
let a = {1, 3, 5, 6} and b = {1, 2, 3, 4} and c = {1, 2, 3, 4, 5, 6}. find the following sets a) ∩ b) ∩ ∩ c) ∪ d) ∪ ∪ e) a-b f) a-(b-c)
Answers
a) This is because these are the only elements that are present in both sets a and b.
b) This is because the only element that is present in all three sets is 1.
c) This is because all the elements in all three sets are present in the union set.
d) This is because all the elements in all three sets are present in the union set.
e) This is because the elements in set a that are not present in set b are 5 and 6.
f) This is because the set difference of b and c is {2, 4}, and when we subtract that from set a, we get all the elements in a.
a) ∩ b) Intersection of sets a and b:
a ∩ b = {1, 3}
This is because these are the only elements that are present in both sets a and b.
b) ∩ ∩ c) Intersection of sets a, b, and c:
a ∩ b ∩ c = {1}
This is because the only element that is present in all three sets is 1.
c) ∪ d) Union of sets a, b, and c:
a ∪ b ∪ c = {1, 2, 3, 4, 5, 6}
This is because all the elements in all three sets are present in the union set.
d) ∪ ∪ e) Union of sets a, b, and c:
a ∪∪ b ∪∪ c = {1, 2, 3, 4, 5, 6}
This is because all the elements in all three sets are present in the union set.
e) a-b) Set difference between sets a and b:
a - b = {5, 6}
This is because the elements in set a that are not present in set b are 5 and 6.
f) a-(b-c)) Set difference between sets a and the set difference of b and c:
b - c = {2, 4}
a - (b - c) = {1, 3, 5, 6}
This is because the set difference of b and c is {2, 4}, and when we subtract that from set a, we get all the elements in a.
for such more question on Intersection
https://brainly.com/question/22008756
#SPJ11
find two sets a and b such that a∈b and a ⊆b.
Answers
One example of two sets a and b such that a∈b and a ⊆b is a = {1} and b = {{1},2}.
Here, a is an element of b because a = {1} is one of the elements of b, and a is also a subset of b because all the elements of a are also in b. Another example could be a = {2,3} and b = {{1},2,3,4}. In this case, a is an element of b because a = {2,3} is one of the elements of b, and a is also a subset of b because all the elements of a are also in b.
In set theory, an element is a member of a set, while a subset is a set that contains all the elements of another set. The notation a∈b means that a is an element of b, while a⊆b means that a is a subset of b.
These concepts are important in understanding the relationship between different sets and how they relate to each other. By finding examples of sets that satisfy both conditions, we can see how these concepts work in practice.
To know more about subset click on below link:
https://brainly.com/question/31739353#
#SPJ11
Phillip throws a ball and it takes a parabolic path. The equation of the height of the ball with respect to time is size y=-16t^2+60t, where y is the height in feet and t is the time in seconds. Find how long it takes the ball to come back to the ground
Answers
The ball takes 3.75 seconds to come back to the ground. The time it takes for the ball to reach the ground can be determined by finding the value of t when y = 0 in the equation y = -[tex]16t^2[/tex] + 60t.
By substituting y = 0 into the equation and factoring out t, we get t(-16t + 60) = 0. This equation is satisfied when either t = 0 or -16t + 60 = 0. The first solution, t = 0, represents the initial time when the ball is thrown, so we can disregard it. Solving -16t + 60 = 0, we find t = 3.75. Therefore, it takes the ball 3.75 seconds to come back to the ground.
To find the time it takes for the ball to reach the ground, we set the equation of the height, y, equal to zero since the height of the ball at ground level is zero. We have:
-[tex]16t^2[/tex] + 60t = 0
We can factor out t from this equation:
t(-16t + 60) = 0
Since we're interested in finding the time it takes for the ball to reach the ground, we can disregard the solution t = 0, which corresponds to the initial time when the ball is thrown.
Solving -16t + 60 = 0, we find t = 3.75. Therefore, it takes the ball 3.75 seconds to come back to the ground.
Learn more about equation here:
https://brainly.com/question/29657988
#SPJ11